How scores are computed
The math behind feasibility — weights, dimensions, composite, and what unknown data does.
The feasibility score you see on each route is a weighted composite of five independent dimensions. This page documents how the math actually works, so you can reason about edge cases (missing data, custom weights, tie-breaking) without having to reverse-engineer the UI.
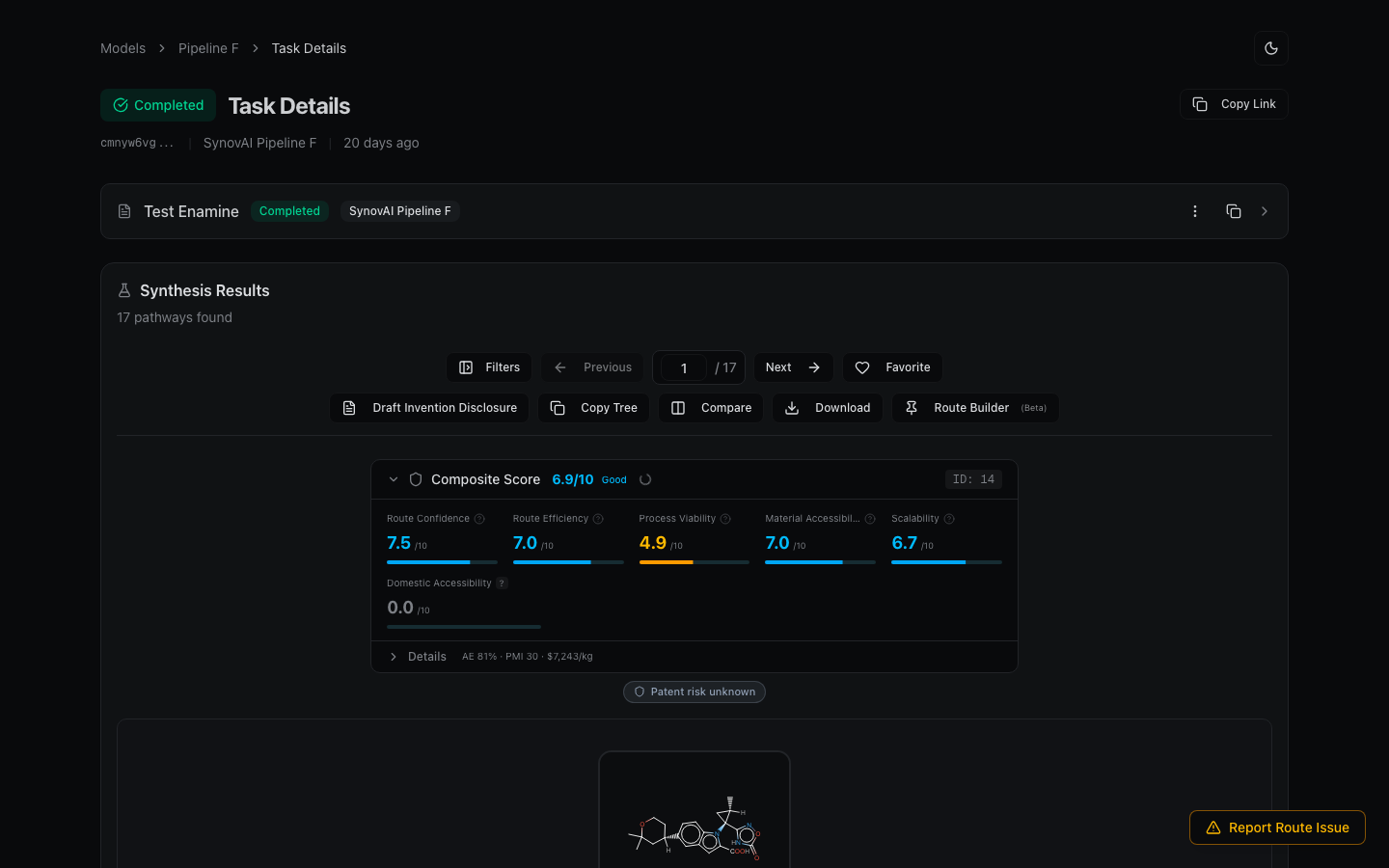
The five dimensions
Each dimension produces a raw 0–10 score independently:
- Route Confidence — learned from model similarity to training data.
- Scalability — derived from reaction-class heuristics (cryogenic? chromatography? exotic catalysts?).
- Material Accessibility — computed from PubChem vendor coverage of leaf nodes.
- Route Efficiency — structural: step count, LLS, branching, starting-material complexity.
- Process Viability — a sub-composite of EcoScale, solvent sustainability, hazard count, and E-factor.
Each dimension is computed independently — no dimension depends on another. This is deliberate: when you inspect a low-scoring route, you want to know which specific concern is dragging it down.
The composite
The overall feasibility score is:
score = Σ (dimension_i × weight_i) / Σ weight_i
Default weights:
| Dimension | Default weight |
|---|---|
| Route Confidence | 25% |
| Material Accessibility | 20% |
| Scalability | 15% |
| Route Efficiency | 15% |
| Process Viability | 15% |
Custom scoring profiles override these weights. The remaining 10% of the default composite is reserved for future dimensions and currently just leaves the defaults summing to 90% — the denominator in the weighted average is the sum of active weights, so this doesn't distort the score.
Handling unknown data
Some dimensions depend on async data. Material Accessibility, for example, requires PubChem vendor lookups to complete. Before that data arrives:
- The dimension displays
?instead of a number. - That dimension's weight is removed from the denominator.
- The remaining weights are renormalized so the composite still sums to 100% of what's available.
This means an early-render feasibility score and a fully-loaded one can differ, but both are internally consistent.
Tie-breaking
When two routes produce identical composite scores (rare but possible on small step-count search results), the ordering is stable across sort operations — we use the generation order from the search as the tie-breaker. This means the same query always returns routes in the same order even when scores collide.
Scoring profiles vs. filters
See Scoring profiles for the built-in profiles and how to define custom ones.